Overview of Kimi K2.5 Model
Kimi K2.5 is Kimi’s most intelligent model to date, achieving open-source SoTA performance in Agent, code, visual understanding, and a range of general intelligent tasks. It is also Kimi’s most versatile model to date, featuring a native multimodal architecture that supports both visual and text input, thinking and non-thinking modes, and dialogue and Agent tasks. Tech Blog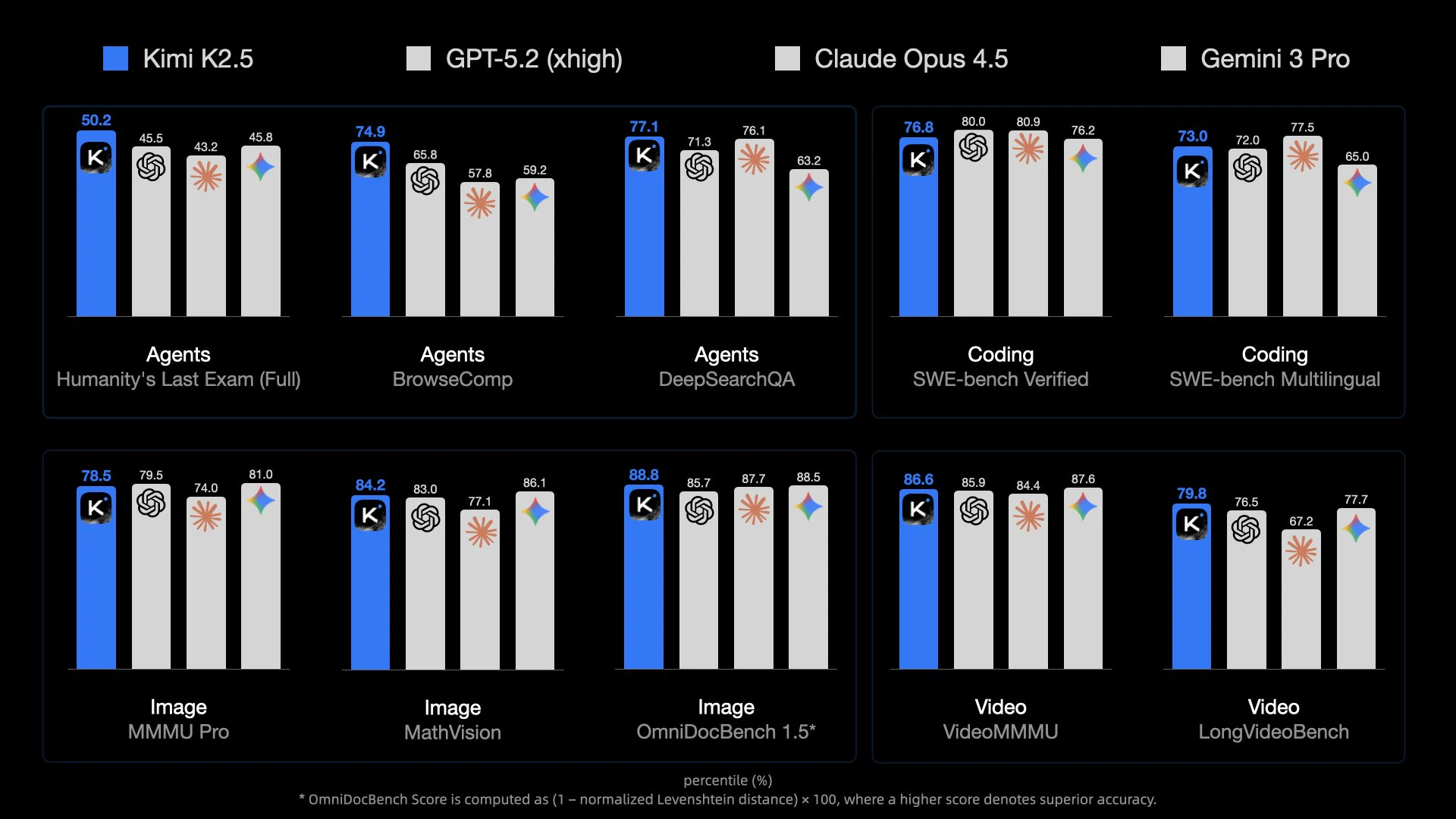
Breakthrough in Coding Capabilities
- As a leading coding model in China, Kimi K2.5 builds upon its full-stack development and tooling ecosystem strengths, further enhancing frontend code quality and design expressiveness. This major breakthrough enables the generation of fully functional, visually appealing interactive user interfaces directly from natural language, with precise control over complex effects such as dynamic layouts and scrolling animations.
Ultra-Long Context Support
kimi-k2.5,kimi-k2-0905-Preview,kimi-k2-turbo-preview,kimi-k2-thinking, andkimi-k2-thinking-turbomodels all provide a 256K context window.
Long-Thinking Capabilities
kimi-k2.5still has strong reasoning capabilities, supporting multi-step tool invocation and reasoning, excelling at solving complex problems, such as complex logical reasoning, mathematical problems, and code writing.
Example Usage
Here is a complete usage example to help you quickly get started with the Kimi K2.5 model.Install the OpenAI SDK
Kimi API is fully compatible with OpenAI’s API format. You can install the OpenAI SDK as follows:Verify the Installation
Quick Start
- Try it now: Test model performance in your business scenarios through interactive operations in the Dev Workbench
- Apply for API Key: Test via API call immediately
Image Understanding Code Example
Video Understanding Code Example
Multimodal Tool Capability Example
Kimi K2.5 model combines multiple capabilities. The following example demonstrates K2.5’s visual understanding + tool calling capabilities. First, download this sample video to your local machine, such as~/Download/test_video.mp4
Best Practices
Supported Formats
Images are supported in formats: png, jpeg, webp, gif.Videos are supported in formats: mp4, mpeg, mov, avi, x-flv, mpg, webm, wmv, 3gpp.
Token Calculation and Billing
Image and video token usage is dynamically calculated. You can use the token estimation API to check the expected token consumption for a request containing images or video before processing. Generally, the higher the resolution of an image, the more tokens it will consume. For videos, the number of tokens depends on the number of keyframes and their resolution—the more keyframes and the higher their resolution, the greater the token consumption. The Vision model uses the same billing method as themoonshot-v1 model series, with charges based on the total number of tokens processed. For more information, see:
For token pricing details, refer to Model Pricing.
Recommended Resolution
We recommend that image resolution should not exceed 4k (4096×2160), and video resolution should not exceed 2k (2048×1080). Higher resolutions will only increase processing time and will not improve the model’s understanding.Upload File or Base64?
Due to the limitation on the overall size of the request body, for very large videos you must use the file upload method to utilize vision capabilities.For images or videos that will be referenced multiple times, it is recommended to use the file upload method. Regarding file upload limitations, please refer to the File Upload documentation. Image quantity limit: The Vision model has no limit on the number of images, but ensure that the request body size does not exceed 100M URL-formatted images: Not supported, currently only supports base64-encoded image contentParameters Differences in Request Body
Parameters are listed in chat. However, behaviour of some parameters may be different in k2.5 models. We recommend using the default values instead of manually configuring these parameters. Differences are listed below.| Field | Required | Description | Type | Values |
|---|---|---|---|---|
| max_tokens | optional | The maximum number of tokens to generate for the chat completion. | int | Default to be 32k aka 32768 |
| thinking | optional | New! This parameter controls if the thinking is enabled for this request | object | Default to be {"type": "enabled"}. Value can only be one of {"type": "enabled"} or {"type": "disabled"} |
| temperature | optional | The sampling temperature to use | float | k2.5 model will use a fixed value 1.0, non-thinking mode will use a fixed value 0.6. Any other value will result in an error |
| top_p | optional | A sampling method | float | k2.5 model will use a fixed value 0.95. Any other value will result in an error |
| n | optional | The number of results to generate for each input message | int | k2.5 model will use a fixed value 1. Any other value will result in an error |
| presence_penalty | optional | Penalizing new tokens based on whether they appear in the text | float | k2.5 model will use a fixed value 0.0. Any other value will result in an error |
| frequency_penalty | optional | Penalizing new tokens based on their existing frequency in the text | float | k2.5 model will use a fixed value 0.0. Any other value will result in an error |
Tool Use Compatibility
When using tools, if the thinking parameter is set to{"type": "enabled"}, please note the following constraints to ensure model performance:
tool_choicecan only be set to “auto” or “none” (default is “auto”) to avoid conflicts between reasoning content and the specified tool_choice. Any other value will result in an error;- During multi-step tool calling, you must keep the
reasoning_contentfrom the assistant message in the current turn’s tool call within the context, otherwise an error will be thrown; - The official builtin
$web_searchtool is temporarily incompatible with Kimi K2.5 thinking mode, you can choose to disable thinking mode first and then use the$web_searchtool.
Disable Thinking Capability Example
For thekimi-k2.5 model, you can disable thinking by specifying "thinking": {"type": "disabled"} in the request body:
- curl
- python
Model Pricing
| Model | Unit | Input Price (Cache Hit) | Input Price (Cache Miss) | Output Price | Context Window |
|---|---|---|---|---|---|
kimi-k2.5 | 1M tokens | $0.10 | $0.60 | $3.00 | 262,144 tokens |
For the full pricing page, including other model families and billing notes, see Chat Pricing.
Learn More
- For the benchmark testing with Kimi K2.5, please refer to this benchmark best practice
- For the most detailed API usage example of Kimi K2.5, see: How to Use Kimi Vision Model
- See How to Use Kimi K2 in Claude Code, Roo Code, and Cline
- Learn how to configure and use the Thinking Model
- Web search is a powerful official tool provided by the Kimi API. See how to use Web Search and other official tools.
- For all model pricing see here, Billing & Rate Limit details, and Web Search Pricing